

How to Implement Linear Regression in Python
Table of Contents
Introduction to Linear Regression
Linear regression is one of the most widely used statistical methods for modeling the relationship between a dependent variable and one or more independent variables. At its core, linear regression seeks to find the best-fitting straight line—known as the regression line—that predicts the outcome variable from the input features. This technique is foundational in predictive modeling because of its simplicity, interpretability, and efficiency.
Linear regression is applicable in many domains such as finance, healthcare, and marketing, where understanding relationships between variables is crucial. For example, predicting housing prices based on features like square footage and location, or forecasting a company’s revenue based on advertising spend, are classic examples of linear regression in action.
Implementing Linear Regression in Python
Now, let’s translate this theory into practice. We will use the built-in Diabetes dataset from the scikit-learn library for our demonstration. The Diabetes dataset is a classic example, frequently used to showcase linear regression, where features such as body mass index (BMI), blood pressure, and others are used to predict a measure of disease progression.
Step 1: Installing and Importing Required Libraries
Before beginning, ensure you have installed Python and the necessary libraries. You can install them using pip:
!pip install numpy pandas scikit-learn matplotlibNow, import the libraries in your Python script or Jupyter Notebook:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.datasets import load_diabetes
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error, r2_scoreStep 2: Loading the Built-In Dataset
We will load the Diabetes dataset from scikit-learn. This dataset contains several features (predictors) and a target variable representing the disease progression.
# Load the Diabetes dataset, identify dimensions and features
dataset = load_diabetes()
X = dataset.data
y = dataset.target
# Display the name of dimensions and features
print("Dataset dimensions:", X.shape)
print("Feature names:", dataset.feature_names)This dataset provides a great example of how real-world data can be used to build and evaluate a predictive model.
Step 3: Splitting the Dataset
It is crucial to evaluate your model on unseen data. Therefore, we will split the dataset into training and testing sets using scikit-learn’s train_test_split().
# Split the dataset into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
print("Training set dimensions:", X_train.shape)
print("Test set dimensions:", X_test.shape)Splitting the data ensures that your model’s performance is evaluated objectively.
Step 4: Training the Linear Regression Model
With the data prepared, we can now create an instance of the LinearRegression class and train it on our training dataset.
# Create and train the regression model
model = LinearRegression()
model.fit(X_train, y_train)The model learns the relationship between the input features and the target variable by estimating the optimal values of the coefficients.
Step 5: Evaluating the Model
Once the model is trained, we evaluate its performance on the test set. The key metrics for regression include the Mean Squared Error (MSE) and the Coefficient of Determination (R²).
# predictions based on the test set
y_pred = model.predict(X_test)
# evaluation of model
mse = mean_squared_error(y_test, y_pred)
r2 = r2_score(y_test, y_pred)
print("Mean Squared Error:", mse)
print("R² score:", r2)An R² score close to 1 indicates that the model explains a large proportion of the variance in the target variable.
Step 6: Visualizing the Results
Visualizations help in understanding model performance. Although the Diabetes dataset is multidimensional, we can visualize predictions for one feature for illustrative purposes.
# For visualization, we take one feature (e.g., BMI which is diabetes.feature_names[2])
bmi_train = X_train[:, 2]
bmi_test = X_test[:, 2]
# Ploting actual vs. predicted
plt.scatter(bmi_test, y_test, color='blue', label='Actual')
plt.scatter(bmi_test, y_pred, color='red', label='Predicted')
plt.title('Linear Regression: Actual vs Predicted')
plt.xlabel('BMI')
plt.ylabel('Disease Progression')
plt.legend()
plt.show()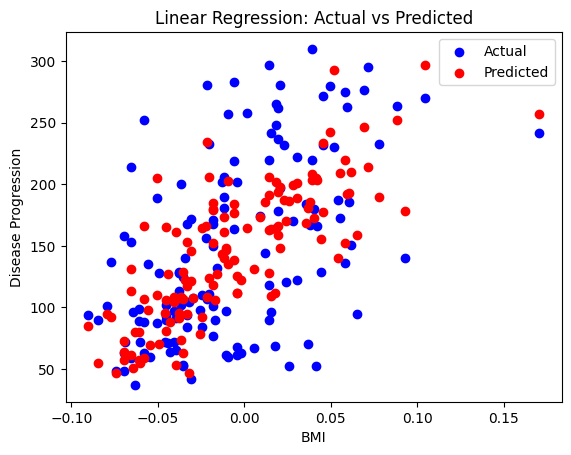
Even if a single feature doesn’t capture all variability, such plots provide insight into how well the model performs on individual dimensions.
Step 7: Making Predictions on New Data
One of the ultimate goals of predictive modeling is to forecast outcomes on new, unseen data. You can simply pass new input values to your model’s .predict() method.
#generate 10 new values for prediction
new_observations = 10
X_new = np.linspace(np.min(X_test), np.max(X_test), new_observations).reshape(-1, X_test.shape[1])
y_new = model.predict(X_new)
print("Predicted values", y_new)This step demonstrates the model’s ability to generalize beyond the training data.
Step 8: Advanced Evaluation Techniques
While MSE and R² are fundamental, further evaluation using cross-validation or residual analysis can offer deeper insights into model performance. For example, plotting the residuals (the differences between actual and predicted values) can reveal whether any patterns or biases exist.
A random scatter of residuals around zero suggests that the model’s errors are uniformly distributed, an essential assumption for linear regression.
Career Corner: Essential Skills for Data Scientists
Staying current in the field of data science requires mastering both foundational and advanced techniques. Linear regression is often one of the first models a data scientist learns. However, as you progress in your career, you’ll need to build upon this foundation by exploring more complex models and statistical methods.
Key Skills for Data Scientists:
- Statistical Analysis and Modeling: Understanding the assumptions and mathematics behind models like linear regression.
- Programming Proficiency: Python remains the dominant language; mastering libraries such as NumPy, Pandas, and scikit-learn is essential.
- Data Visualization: The ability to communicate insights through effective visualizations is critical.
- Model Evaluation and Tuning: Learn to evaluate models not only using basic metrics (like MSE and R²) but also through cross-validation and residual analysis.
- Continuous Learning: Attend workshops, webinars, and conferences to stay updated with the latest trends and techniques.
Developing these skills will not only enhance your technical abilities but also increase your marketability in the competitive world of data science.
Tech Trends Spotlight: The Future of Predictive Modeling
Predictive modeling is rapidly evolving. Here are some emerging trends in the field:
- Integration of Machine Learning and Deep Learning: While linear regression is a fundamental tool, its integration with deep learning techniques is paving the way for hybrid models that combine interpretability with performance.
- Automated Machine Learning (AutoML): Tools that automatically select the best model and tune its parameters are becoming more prevalent, enabling faster deployment of predictive systems.
- Explainable AI (XAI): As machine learning models become more complex, there is a growing demand for models that are interpretable. Linear regression serves as an excellent baseline for explaining more complicated models.
- Edge Computing and Real-Time Predictions: With the proliferation of IoT devices, real-time predictive modeling is increasingly important. Lightweight models like linear regression are often used in combination with more advanced techniques to achieve fast predictions on edge devices.
- Cloud-Based Data Science Platforms: Platforms such as Google Cloud AI, AWS SageMaker, and Azure ML are making it easier to deploy models in production environments, streamlining workflows from data preprocessing to model evaluation.
These trends indicate that while linear regression is a classical approach, its principles continue to underpin more advanced methodologies.
Tools and Resources Recommendations
To further your knowledge and practical skills in linear regression and data science in general, consider exploring the following resources:
- Scikit-Learn Linear Regression: Comprehensive guides and examples on linear regression and other machine learning models.
- Real Python Linear Regression Tutorial: Offers in-depth tutorials on implementing linear regression and other models in Python.
- Jupyter Notebook Resources: Using Jupyter notebooks for interactive learning can greatly enhance your understanding. Consider exploring notebooks on platforms like Kaggle and GitHub.
- Online Courses and Tutorials
- Online Courses and Tutorials – Coursera’s “Machine Learning” by Andrew Ng: An excellent course that covers the basics of regression and beyond.
- Online Courses and Tutorials – Udacity’s “Intro to Machine Learning with PyTorch”: Focuses on practical applications and hands-on projects.
- GitHub Repositories
- GitHub Repositories – Scikit-Learn GitHub – Explore examples, documentation, and community contributions.
- GitHub Repositories – Machine Learning Projects – A repository of practical projects and notebooks covering linear regression, among other techniques.
- GitHub Repositories – Awesome Machine Learning – A curated list of resources and projects for aspiring data scientists
Call to Action
Now that you have a comprehensive guide to implementing linear regression in Python, it’s time to put your knowledge into practice. Here’s what you can do next:
- Download a Built-In Dataset: Start with the Diabetes dataset or the California Housing dataset from scikit-learn and replicate the examples provided.
- Experiment: Modify the code to test different train-test splits, feature selections, and evaluation metrics.
- Share Your Projects: Contribute your work to open-source communities like GitHub or engage with fellow data scientists on LinkedIn.
- Join Our Community: Become a member of the Data Science Demystified Network on LinkedIn to exchange ideas, ask questions, and share your successes.
- Provide Feedback: We value your insights! Let us know which parts of this article were most helpful and what topics you’d like us to cover next.
By taking these steps, you’ll be well on your way to mastering not only linear regression but also the broader field of predictive analytics.
Closing Thoughts
In this article, we explored the robust world of linear regression in Python—from understanding the theory behind the model to implementing it with built-in datasets using scikit-learn. We covered essential steps including data preprocessing, model training, evaluation, and even advanced topics like residual analysis and model validation. The journey of mastering linear regression is not just about learning the code; it’s about developing a deep understanding of how data drives predictions and how to interpret model outputs to make informed decisions.
As you continue your journey in data science, remember that foundational techniques like linear regression serve as the building blocks for more advanced methods. Embrace continuous learning, remain curious, and never hesitate to experiment with different models and approaches.
Thank you for being a valued member of our community. We hope this guide has provided you with actionable insights and inspired you to delve deeper into predictive modeling. Stay tuned for our upcoming editions, where we will explore even more exciting topics in data science and machine learning.
References and Additional Resources:
- Scikit-Learn Linear Models Documentation: https://scikit-learn.org/stable/modules/linear_model.html
- Real Python’s Linear Regression Tutorial: https://realpython.com/linear-regression-in-python/
- Machine Learning Projects Repository (Hands-On ML): https://github.com/ageron/handson-ml
- Awesome Machine Learning GitHub: https://github.com/josephmisiti/awesome-machine-learning
- Additional resource on linear regression theory: Wikipedia: Linear Regression
This post was created to empower you with both theoretical insights and practical skills for implementing linear regression using Python. Happy coding and keep pushing the boundaries of what data can achieve!
#LinearRegression #Python #DataScience #MachineLearning #ScikitLearn #AI #TechTrends #DataAnalytics #PredictiveModeling #DeepLearning

